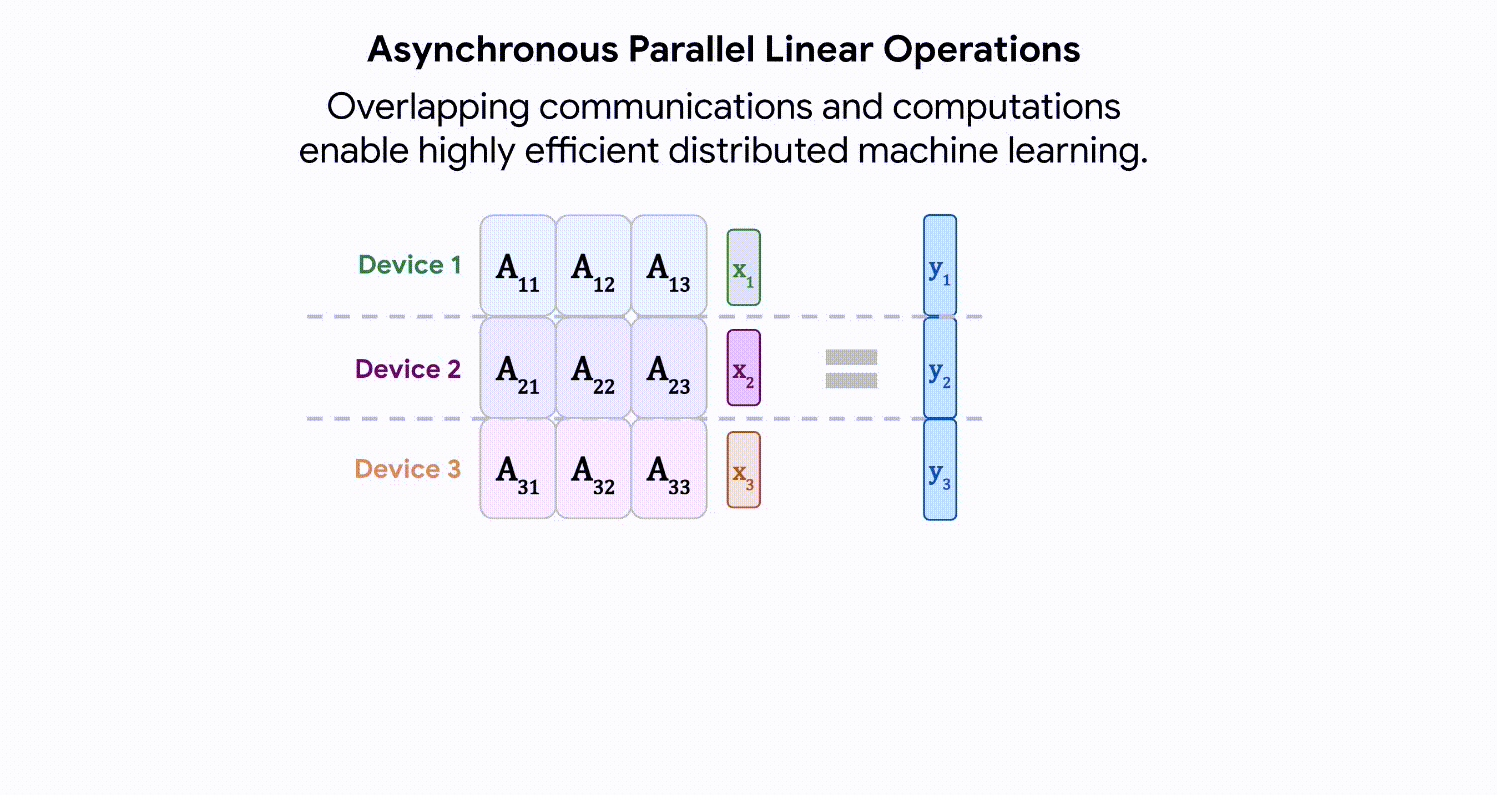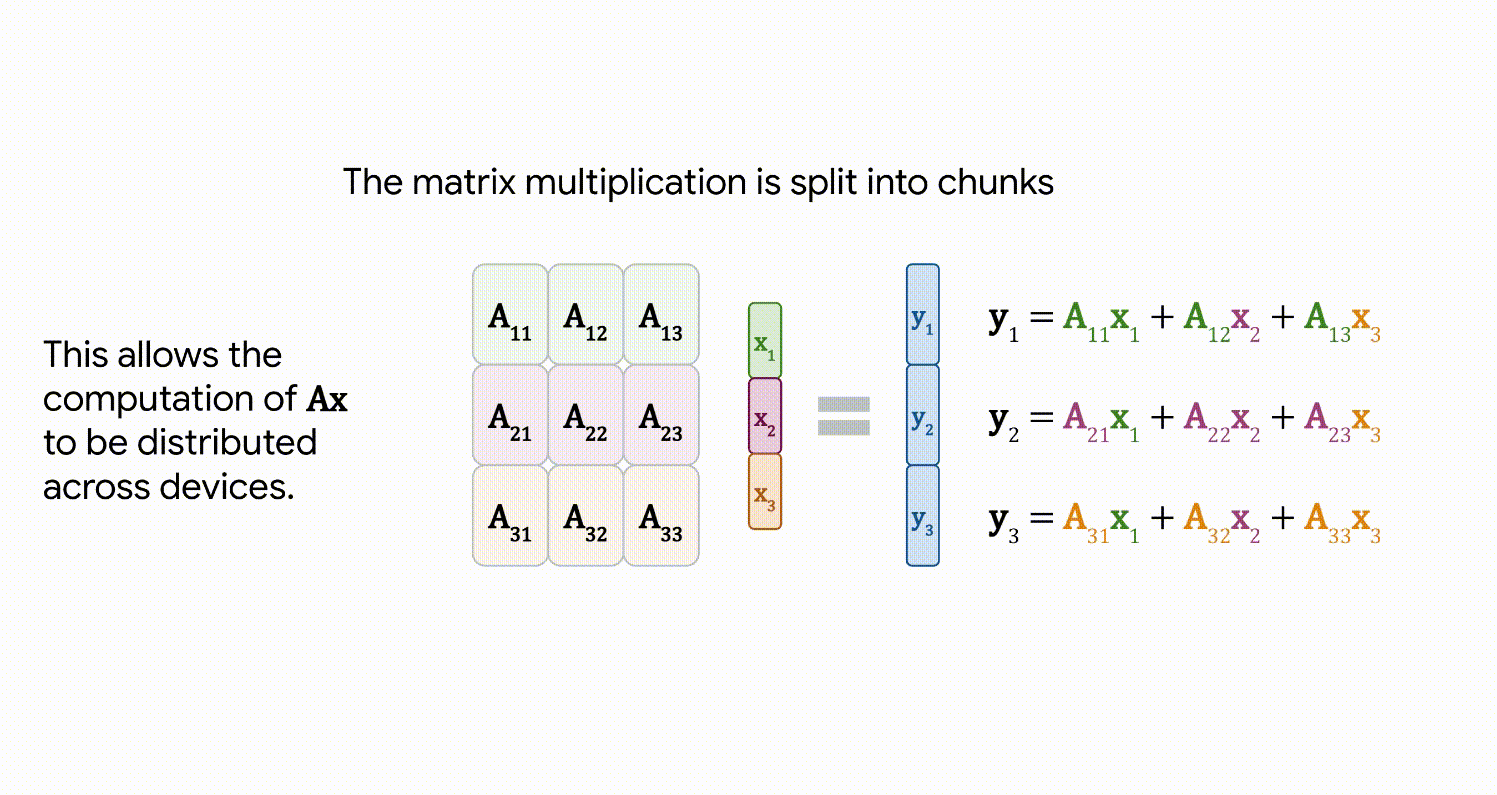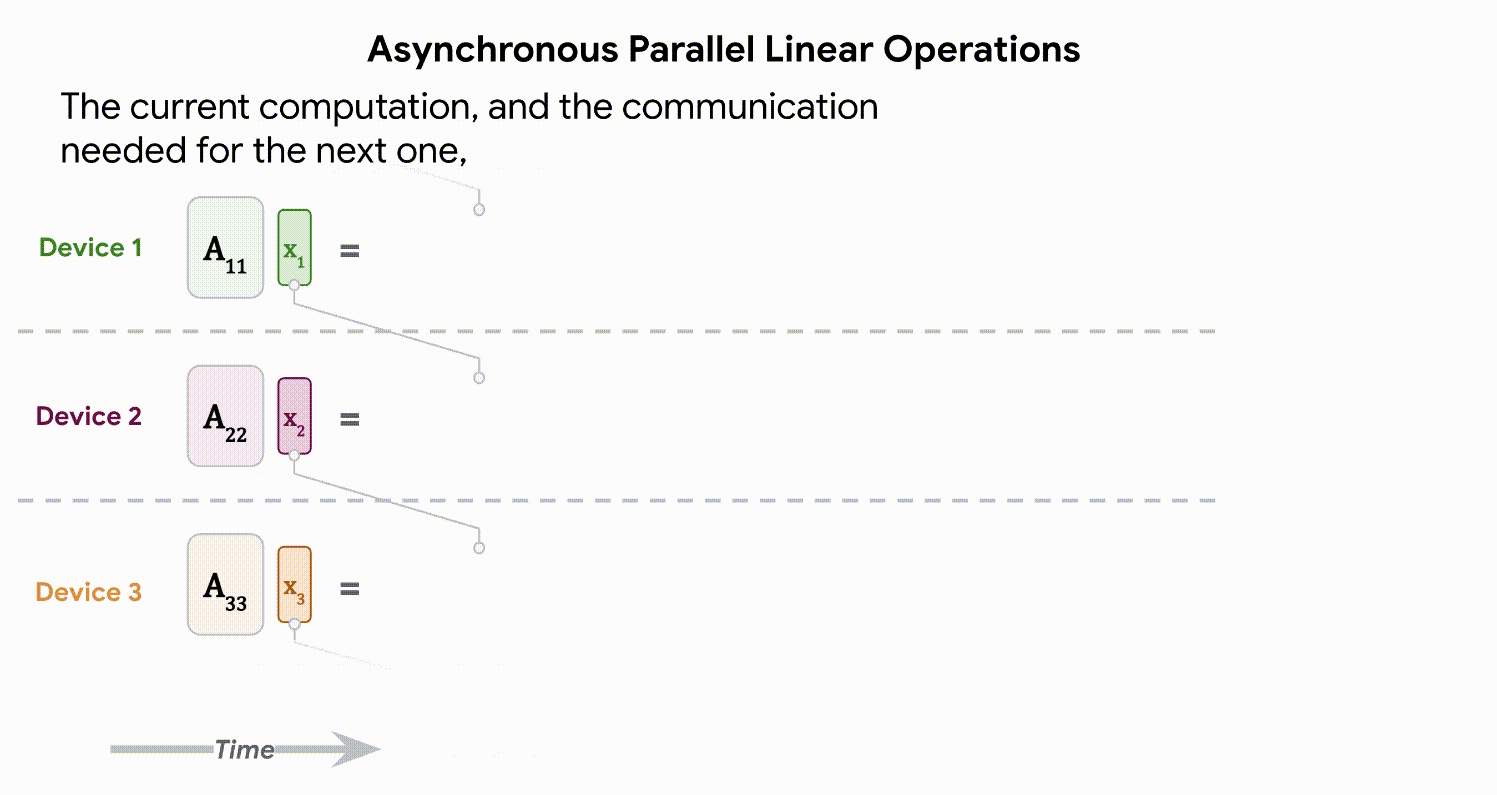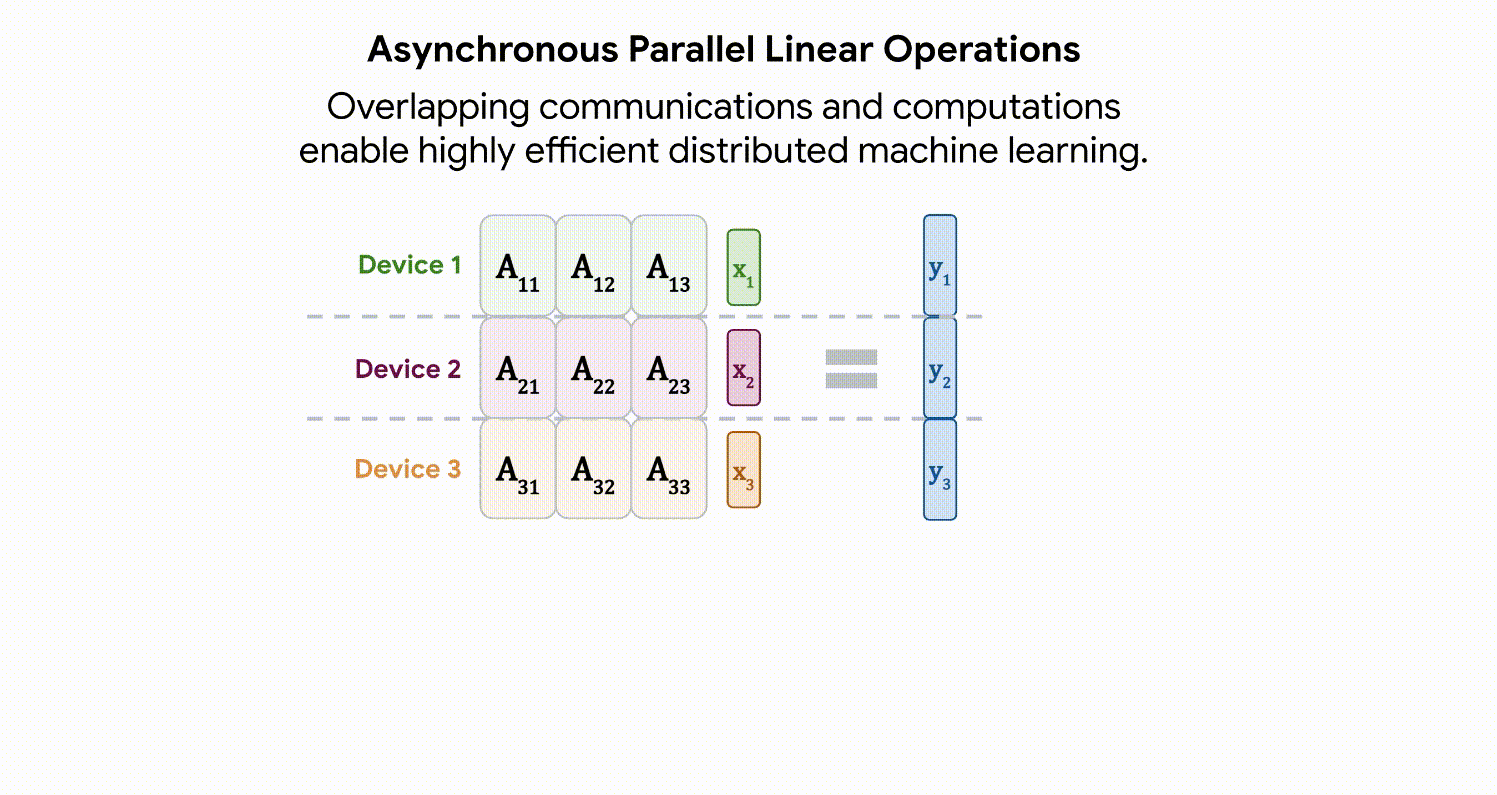
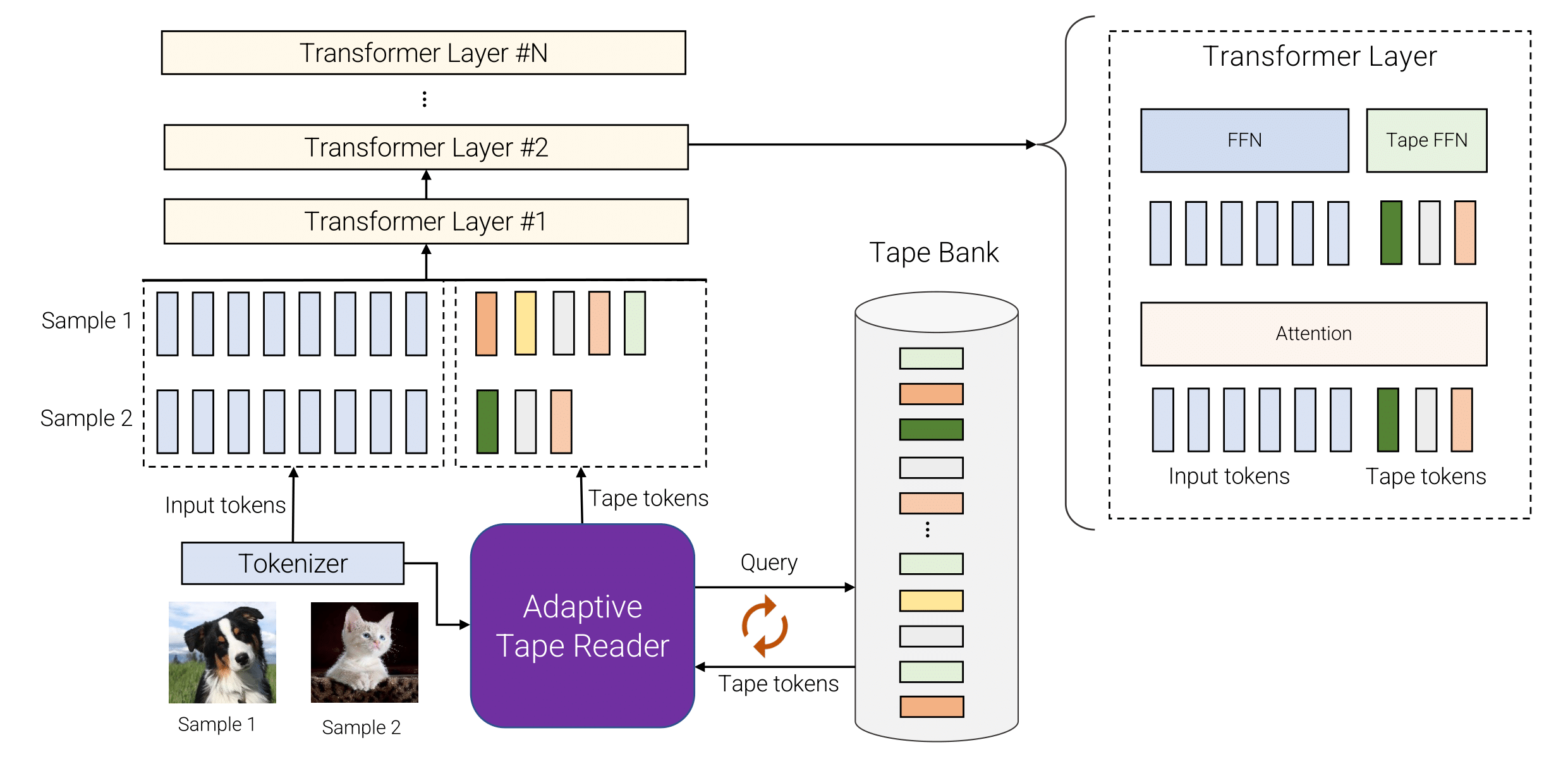
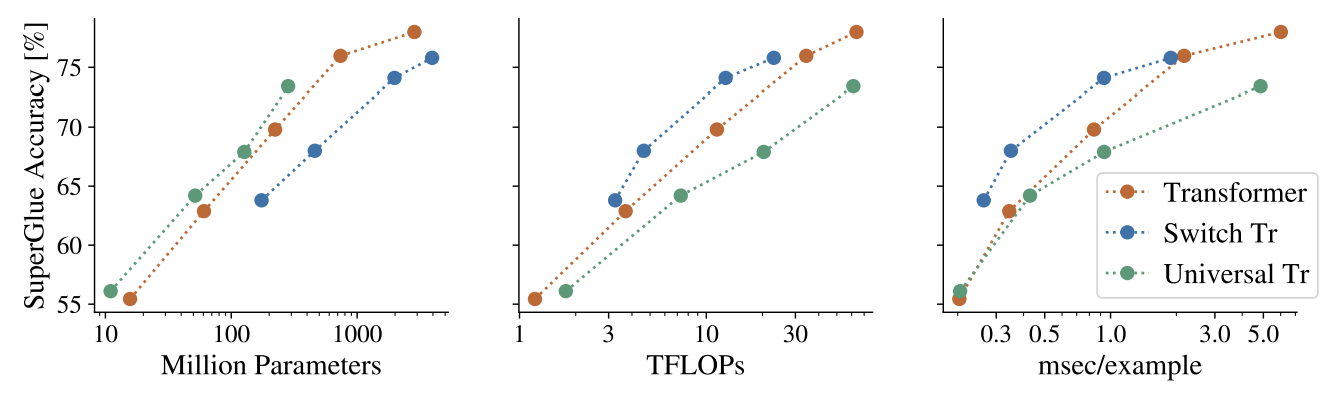
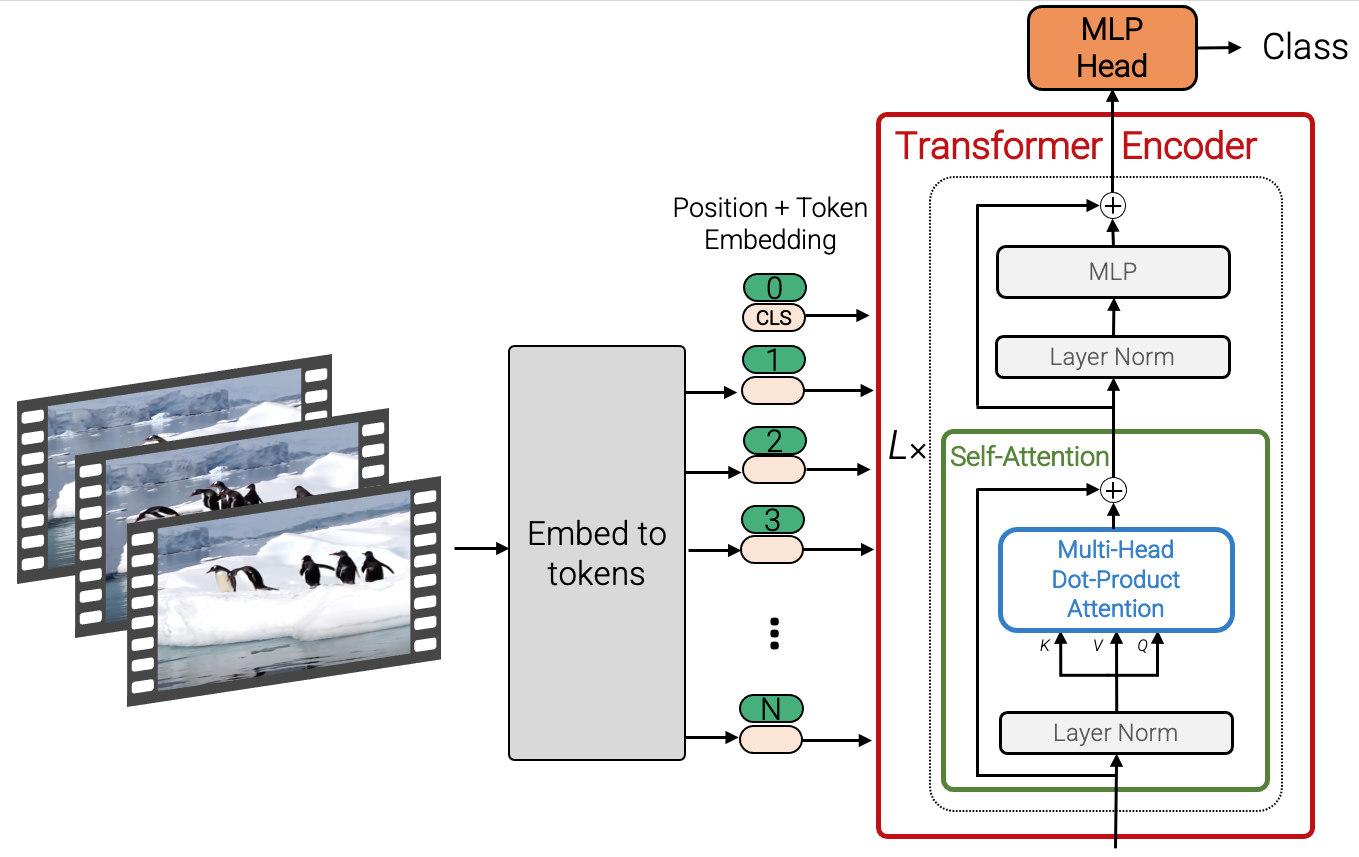
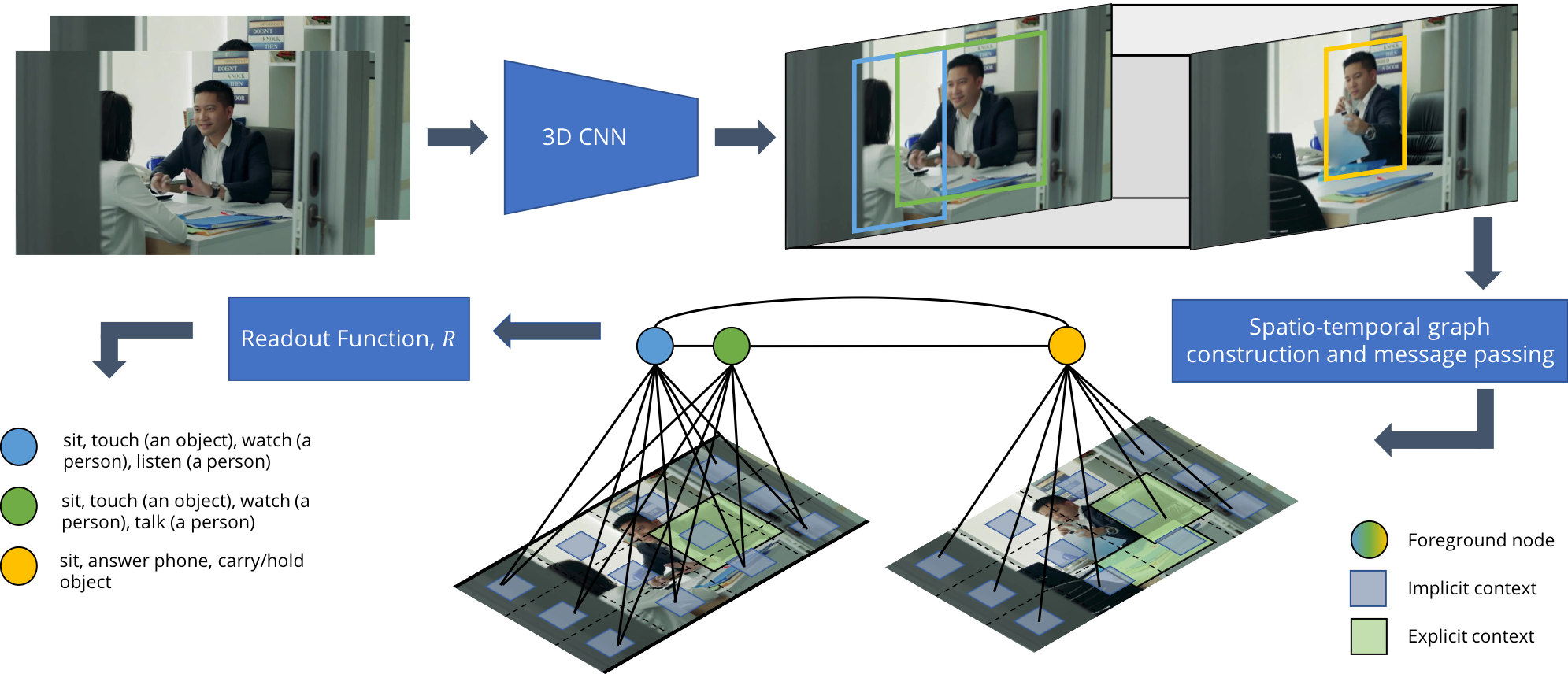
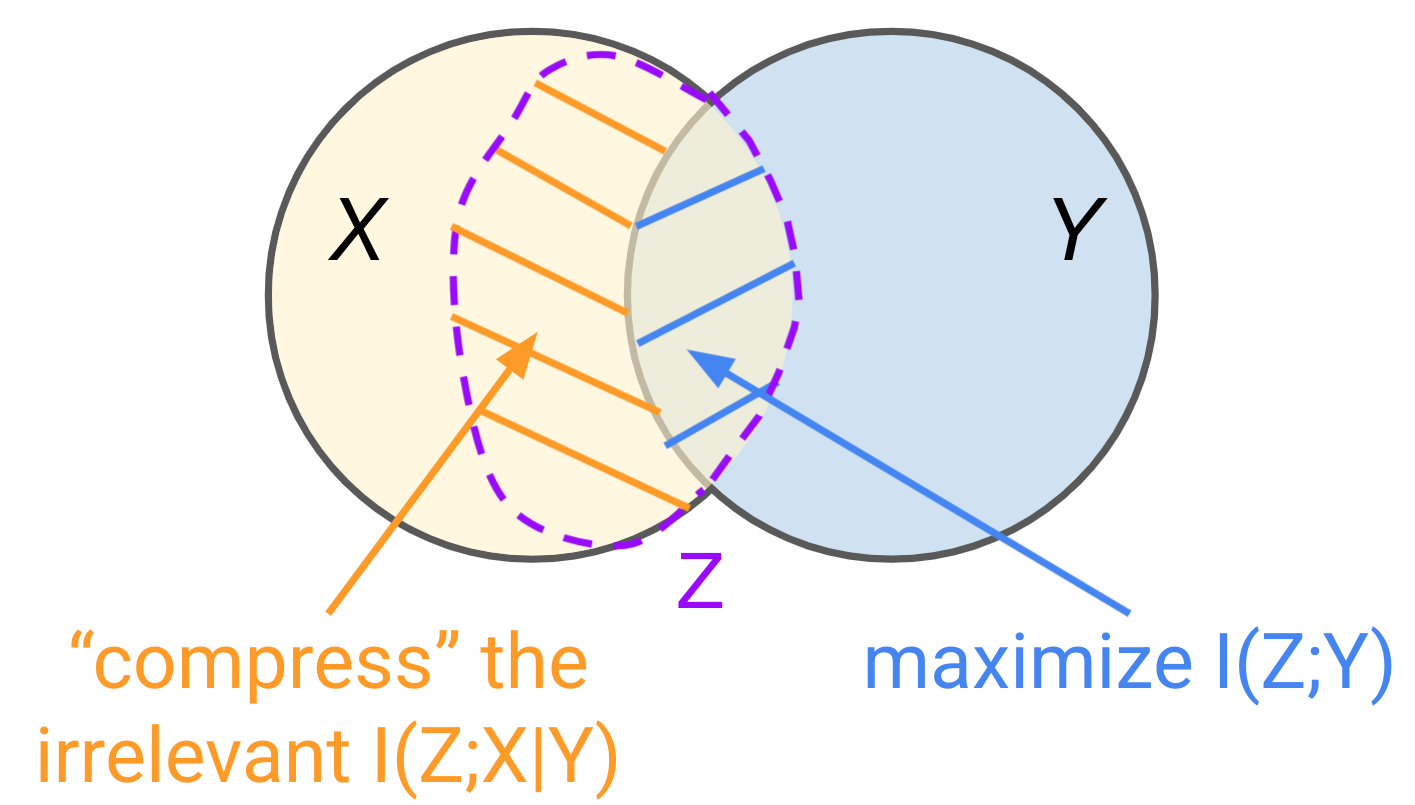
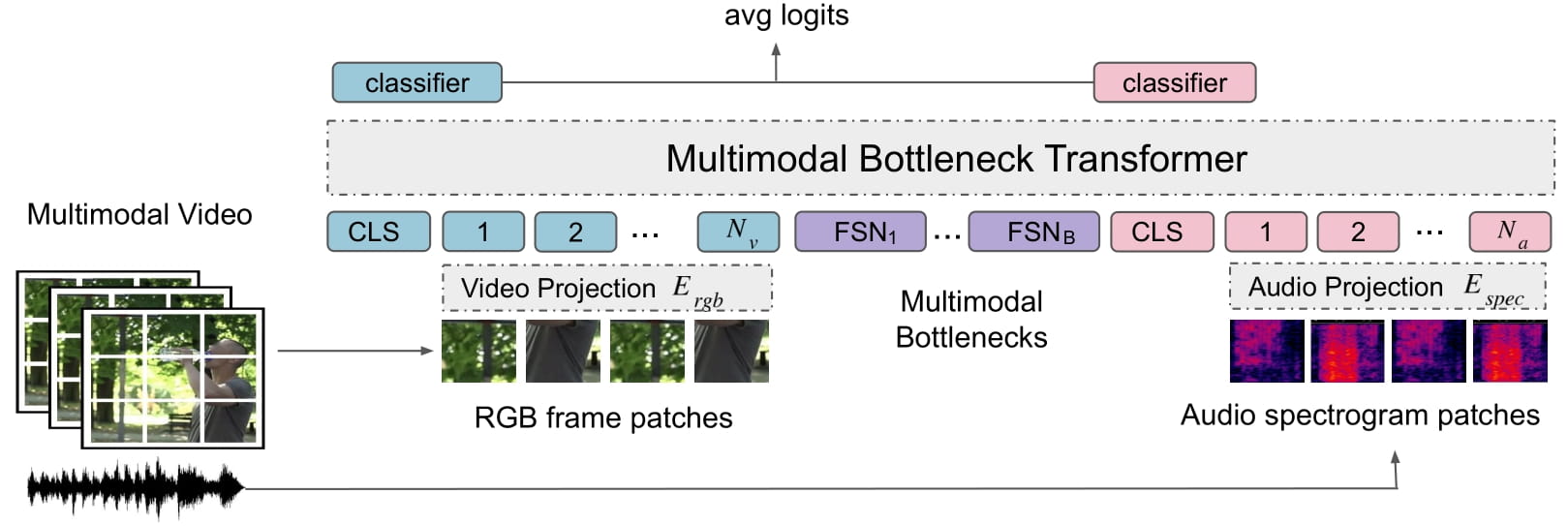
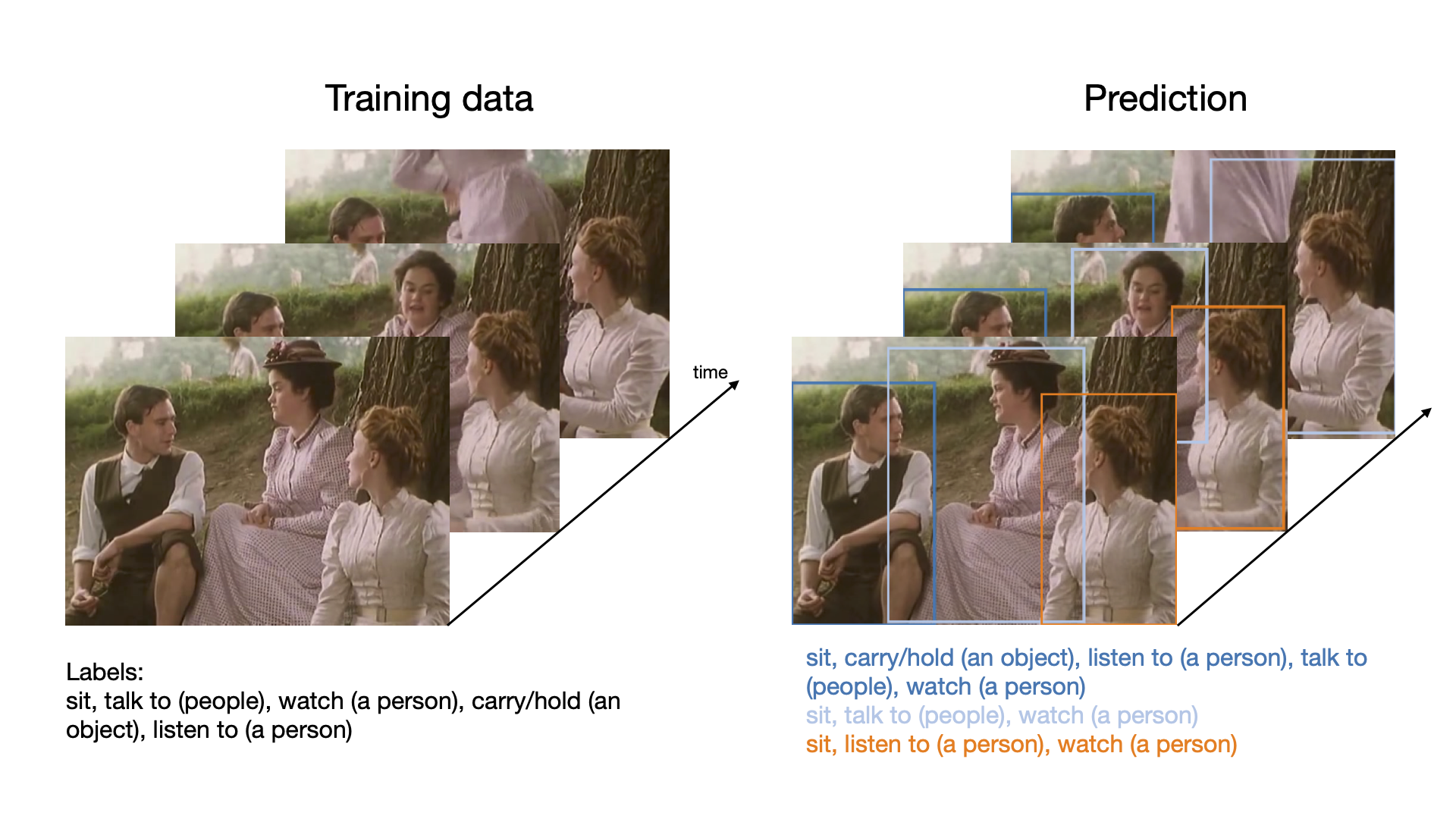
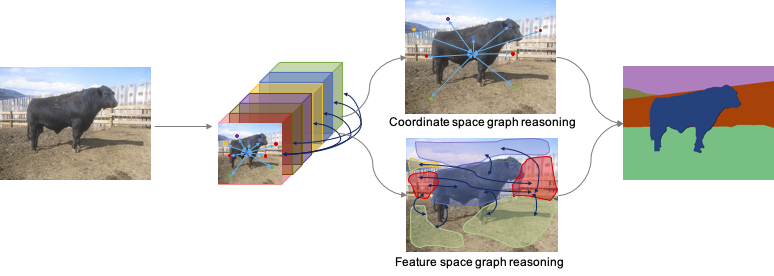
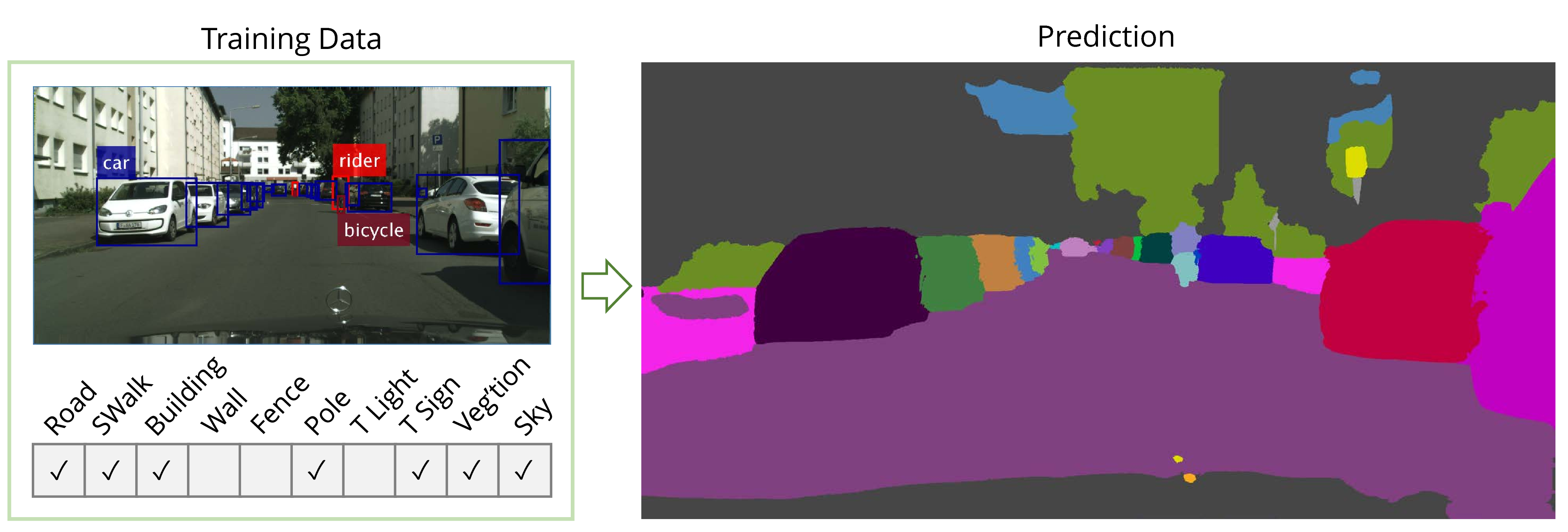
Advanced Architectures for Vision
Invited talk at
African Computer Vision Summer School (ACVSS) at Nairobi, Kenya. July 2024.
[Slides]
Large-Scale Video Understanding with Transformers
Invited talk at
GIST Workshop for Accelerating Intelligence at GIST, South Korea. December 2022.
Invited talk at
Google Visits POSTECH at POSTECH, South Korea. December 2022.
[Slides]
Large-Scale Video Understanding with Transformers
Invited talk at
Holistic Video Understanding Workshop at CVPR. June 2022.
[Slides]
Winning entry to the Epic Kitchens Action Recognition Challenge
Invited talk at
Epic Kitchens Workshop at CVPR. June 2022.
[Slides]
Video Understanding with Imperfect Data
Invited talk at
Learning from Limited and Imperfect Data (L2ID) workshop at CVPR. June 2021.
[Slides]
Transformers: A Review, and Recent Developments in Vision
Invited lecture at
Deep Learning Indaba X Tanzania. June 2021.
[Slides]
Structured Models for Video Understanding
Invited talk at Ulsan National Institute of Science and Technology (UNIST), South Korea. June 2021
[Slides]
Video Understanding in the Wild with Incomplete Supervision
Invited talk at
1st Visual Intelligence Seminar at Fudan University, China. January 2021
[Slides]
Scene Understanding with Deep Structured Models
Invited talk at University of Warsaw. January 2020
[Slides]
Learning from Weak Supervision: Panoptic Segmentation and 3D Human Pose Estimation
Invited talk at
Learning from Imperfect
Data Workshop at CVPR. June 2019
[Slides]
Pixelwise Instance Segmentation with a Dynamically Instantiated Network
ETH Zurich, August 2017
[Slides]
Holistic Scene Understanding with Deep Learning and Dense Random Fields
Invited tutorial at
Deep
Learning Meets Model Optimization and Statistical Inference at
European
Conference on Computer
Vision (ECCV), October 2016.
[Slides]
Joint Object-Material Category Segmentation from Audio-Visual Cues
Vision and Learning Seminar (Online), February 2016
[Video]
Joint Object-Material Category Segmentation from Audio-Visual Cues
CVSSP Seminar, University of Surrey, November 2015
[Slides]